

বিস্তার পরিমাপ (Measures of Dispersion) হলো উপাত্তের ভিন্নতা বা বৈচিত্র্য নির্ধারণের পদ্ধতি। এটি ডেটাসেটের কেন্দ্রীয় প্রবণতা থেকে উপাত্ত কতটা ছড়ানো বা একত্রিত হয়েছে, তা পরিমাপ করতে সাহায্য করে। বিস্তার পরিমাপ আমাদের ডেটার সঠিক বৈচিত্র্য এবং স্থিরতার পরিমাণ বুঝতে সহায়তা করে।
বিস্তার পরিমাপের বিভিন্ন প্রকারভেদ নিম্নরূপ:
সংজ্ঞা:
ডেটাসেটের সর্বাধিক মান এবং সর্বনিম্ন মানের পার্থক্যকে পরিসর বলা হয়।
সূত্র:

উদাহরণ:
ডেটাসেট: ৫, ৭, ১০, ১৫, ২০
পরিসর = ২০ - ৫ = ১৫
বৈশিষ্ট্য:
সংজ্ঞা:
ডেটাসেটের প্রথম চতুর্থাংশ (Q1) এবং তৃতীয় চতুর্থাংশ (Q3) এর মধ্যে পার্থক্যকে চতুর্থাংশ বিস্তার বলা হয়।
সূত্র:
চতুর্থাংশ বিস্তার = Q3 - Q1
উদাহরণ:
ডেটাসেট: ১, ৩, ৫, ৭, ৯, ১১, ১৩
Q1 = ৩, Q3 = ১১
চতুর্থাংশ বিস্তার = ১১ - ৩ = ৮
বৈশিষ্ট্য:
সংজ্ঞা:
গড় থেকে ডেটাসেটের প্রতিটি মানের গড় বিচ্যুতি নির্ণয় করা হয়।
সূত্র:
উদাহরণ:
ডেটাসেট: ২, ৪, ৬, ৮
গড় = (২ + ৪ + ৬ + ৮) / ৪ = ৫
গড় বিচ্যুতি = [(|২-৫|) + (|৪-৫|) + (|৬-৫|) + (|৮-৫|)] / ৪ = ২
বৈশিষ্ট্য:
সংজ্ঞা:
ডেটাসেটের প্রতিটি মান থেকে গড়ের বর্গমূল বিচ্যুতি নির্ণয় করে মানক বিচ্যুতি নির্ধারণ করা হয়।
সূত্র:

উদাহরণ:
ডেটাসেট: ২, ৪, ৬
গড় = (২ + ৪ + ৬) / ৩ = ৪

বৈশিষ্ট্য:
বিস্তার পরিমাপ ডেটাসেটের বৈচিত্র্য ও বিচ্যুতি বুঝতে একটি গুরুত্বপূর্ণ পদ্ধতি। পরিসর, চতুর্থাংশ বিস্তার, গড় বিচ্যুতি, এবং মানক বিচ্যুতি বিভিন্ন ধরনের উপাত্তের বৈচিত্র্য বিশ্লেষণে ব্যবহৃত হয়। ডেটার প্রকৃতি অনুযায়ী সঠিক বিস্তার পরিমাপ বেছে নেওয়া দরকার।
সুইটি সংখ্যার গড় ব্যবধান 3 এবং জ্যামিতিক গড় √7
13, 15, 17, ............ 27 একটি ধারা।
বিস্তার হলো একটি ডেটাসেটের সর্বোচ্চ এবং সর্বনিম্ন মানের মধ্যে পার্থক্য। এটি ডেটাসেটের বিভিন্নতার একটি সহজ পরিমাপ এবং ডেটার বিতরণের প্রাথমিক ধারণা দেয়।
বিস্তার নির্ণয়ের সূত্র:
উদাহরণ:
ডেটাসেট: 5, 10, 15, 20, 25
বিস্তার: 25 - 5 = 20
বিস্তার পরিমাপ ডেটাসেটের মানগুলোর ছড়িয়ে পড়ার মাত্রা বা ডেটা কতটা ছড়ানো তা বোঝায়। এটি মূলত ডেটাসেটের বৈচিত্র্য এবং স্থিতি নির্ধারণে ব্যবহৃত হয়।
ডেটা বিশ্লেষণে বিস্তার পরিমাপ অত্যন্ত গুরুত্বপূর্ণ, কারণ এটি ডেটার গুণমান এবং স্থিতিশীলতার ধারণা দেয়।
বিস্তার পরিমাপ প্রধানত দুটি ভাগে বিভক্ত:
এটি ডেটাসেটের বাস্তব পরিমাপ ব্যবহার করে বিস্তার নির্ণয় করে। সাধারণত এই ধরনের পরিমাপ ডেটাসেটের বিভিন্নতার সঠিক মান প্রকাশ করে। এর প্রধান প্রকারগুলো হলো:
ক. বিস্তার (Range):
সর্বোচ্চ এবং সর্বনিম্ন মানের মধ্যে পার্থক্য।
Range = Maximum Value -Minimum Value
খ. আন্তঃচতুর্থাংশ বিস্তার (Interquartile Range):
ডেটাসেটের ৭৫তম শতাংশক (Q3) এবং ২৫তম শতাংশক (Q1)-এর মধ্যে পার্থক্য।
IQR = Q3 - Q1
গ. চতুর্ভাগীয় বিচ্যুতি (Quartile Deviation):

ঘ. গড় বিচ্যুতি (Mean Deviation):
ডেটাসেটের প্রতিটি মানের গড় থেকে বিচ্যুতির গড়।
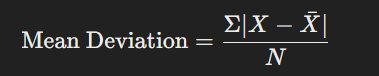
আপেক্ষিক বিস্তার পরিমাপ ডেটার বিভিন্নতার তুলনামূলক মাত্রা নির্দেশ করে এবং এটি সাধারণত শতাংশে প্রকাশিত হয়। এর প্রধান প্রকারগুলো হলো:
ক. আপেক্ষিক গড় বিচ্যুতি (Relative Mean Deviation):
গড় বিচ্যুতিকে গড়ের সাথে তুলনা করে নির্ণয় করা হয়।

খ. আপেক্ষিক চতুর্ভাগীয় বিচ্যুতি (Relative Quartile Deviation):

গ. আপেক্ষিক মান বিচ্যুতি (Relative Standard Deviation):
ডেটাসেটের মান বিচ্যুতিকে গড় বা মধ্যকের সাথে তুলনা করা হয়।

১. ডেটাসেটের বৈচিত্র্য এবং স্থিতি নির্ধারণে সহায়তা করে।
২. বিভিন্ন ডেটাসেটের তুলনা করতে ব্যবহৃত হয়।
৩. গাণিতিক বিশ্লেষণে ডেটাসেটের স্থায়িত্ব যাচাই করা যায়।
৪. ডেটার চরম মান শনাক্তে সহায়তা করে।
বিস্তার এবং বিস্তার পরিমাপ ডেটাসেটের বৈচিত্র্য বোঝার জন্য গুরুত্বপূর্ণ। এটি ডেটার বিস্তৃতি এবং বিভাজন সম্পর্কে একটি পরিষ্কার ধারণা দেয়। বিভিন্ন ধরনের বিস্তার পরিমাপ বিভিন্ন পরিস্থিতিতে ব্যবহৃত হয়, যা ডেটা বিশ্লেষণে অত্যন্ত কার্যকর।
অনপেক্ষ বা পরম বিস্তার পরিমাপ (Absolute Measures of Dispersion) হলো পরিসংখ্যানের একটি পদ্ধতি, যার মাধ্যমে ডেটাসেটের মানগুলোর মধ্যে বৈচিত্র্য বা বিচ্ছুরণ পরিমাপ করা হয়। এই পরিমাপগুলো সরাসরি মূল ডেটাসেটের একক বা মান ব্যবহার করে ডেটার মধ্যে পরিবর্তনশীলতার মাত্রা নির্ধারণ করে। এর প্রধান প্রকারভেদগুলো হলো:
সংজ্ঞা:
ডেটাসেটের সর্বোচ্চ এবং সর্বনিম্ন মানের মধ্যকার পার্থক্য হলো পরিসর। এটি ডেটার বৈচিত্র্যের একটি সরলতম পরিমাপ।
সূত্র:
Range= সর্বোচ্চ মান - সর্বনিম্ন মান
উদাহরণ:
ডেটাসেট: 5, 8, 12, 20
পরিসর: 20 - 5 = 15
গুণাবলি:
সংজ্ঞা:
ডেটাসেটের প্রথম চতুর্থাংশ (Q1) এবং তৃতীয় চতুর্থাংশ (Q3)-এর মধ্যকার পার্থক্য হলো আন্তর্চতুর্থাংশ বিস্তৃতি। এটি মধ্যবর্তী ৫০% ডেটার বৈচিত্র্য পরিমাপ করে।
সূত্র:
IQR} = Q3 - Q1
উদাহরণ:
ডেটাসেট: 4, 8, 10, 12, 16, 20, 24
Q1 = 8 , Q3 = 20
IQR: 20 - 8 = 12
গুণাবলি:
সংজ্ঞা:
ডেটাসেটের প্রতিটি মান এবং গড়ের মধ্যকার পার্থক্যের গড় হলো গড় বিচ্যুতি।
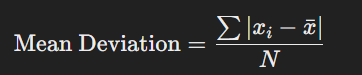
সূত্র:
যেখানে:

উদাহরণ:
ডেটাসেট: 5, 7, 9
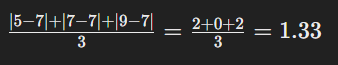
গুণাবলি:
সংজ্ঞা:
ডেটাসেটের প্রতিটি মান এবং গড়ের মধ্যকার বিচ্যুতি (Deviation)-এর বর্গের গড়ের বর্গমূল হলো মানক বিচ্যুতি। এটি ডেটার বৈচিত্র্য পরিমাপের সবচেয়ে গুরুত্বপূর্ণ এবং ব্যাপকভাবে ব্যবহৃত পদ্ধতি।
সূত্র:
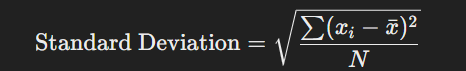
উদাহরণ:
ডেটাসেট: 6, 8, 10
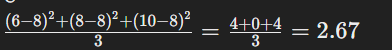
Standard Deviation:
গুণাবলি:
সংজ্ঞা:
ডেটাসেটের প্রতিটি মান এবং গড়ের মধ্যকার বিচ্যুতির বর্গের গড় হলো বৈচিত্র্যের যোগফল।
সূত্র:
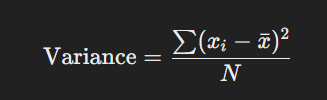
গুণাবলি:
অনপেক্ষ বা পরম বিস্তার পরিমাপের বিভিন্ন পদ্ধতি ডেটাসেটের ভিন্ন ভিন্ন বৈচিত্র্য বিশ্লেষণে কার্যকর। সরল পরিসর থেকে শুরু করে মানক বিচ্যুতি পর্যন্ত প্রতিটি পদ্ধতি নির্দিষ্ট প্রেক্ষাপটে ডেটার বৈচিত্র্য বা বিচ্যুতি বিশ্লেষণে সহায়ক।
বিস্তার পরিমাপ উপাত্তের বৈচিত্র্য বা ছড়ানোর মাত্রা নির্ণয় করে। এটি পরিসংখ্যান বিশ্লেষণের একটি গুরুত্বপূর্ণ অংশ, যা কেন্দ্রীয় প্রবণতা পরিমাপগুলোর সাথে মিলিত হয়ে ডেটাসেট সম্পর্কে আরও গভীর ধারণা প্রদান করে। নিচে বিস্তার পরিমাপের গুরুত্ব ও প্রয়োজনীয়তা নিয়ে আলোচনা করা হলো:
বিস্তার পরিমাপ একটি ডেটাসেটে উপাত্তের পরিসরের পরিমাণ বা ছড়ানোর মাত্রা প্রকাশ করে। এটি বোঝায় যে উপাত্তগুলি কতটা কাছাকাছি বা দূরে অবস্থিত।
উদাহরণ:
যদি দুটি ক্লাসের পরীক্ষার ফলাফল বিশ্লেষণ করা হয় এবং দেখা যায় একটি ক্লাসের পরিসর ১০ এবং অন্যটির ৩০, তবে বোঝা যায় দ্বিতীয় ক্লাসে বৈচিত্র্য বেশি।
বিস্তার পরিমাপ কেন্দ্রীয় প্রবণতা পরিমাপগুলোর (যেমন গড়, মধ্যক) নির্ভরযোগ্যতা যাচাই করতে সাহায্য করে।
বিস্তার পরিমাপ বিভিন্ন পরিস্থিতিতে কার্যকর সিদ্ধান্ত গ্রহণে সাহায্য করে। এটি ব্যবসা, শিক্ষা, গবেষণা এবং আর্থিক ব্যবস্থাপনায় গুরুত্বপূর্ণ ভূমিকা পালন করে।
উদাহরণ:
দুটি স্টকের মধ্যে যেটির মূল্য বেশি পরিবর্তনশীল (বেশি বিস্তার), সেটি বিনিয়োগের জন্য ঝুঁকিপূর্ণ হতে পারে।
বিভিন্ন ডেটাসেটের বিস্তার নির্ধারণ করে তাদের মধ্যে বৈচিত্র্যের তুলনা করা সম্ভব।
উদাহরণ:
দুটি স্কুলের পরীক্ষার ফলাফলের বিস্তার পরিমাপ করে বোঝা যায় কোন স্কুলে শিক্ষার্থীদের মধ্যে ফলাফলের বৈচিত্র্য বেশি।
বিস্তার পরিমাপের মাধ্যমে ডেটা কতটা স্থির বা পরিবর্তনশীল তা বোঝা যায়। কম বিস্তার স্থায়িত্ব নির্দেশ করে এবং বেশি বিস্তার পরিবর্তনশীলতা নির্দেশ করে।
যে কোনো গবেষণা বা বিশ্লেষণের জন্য ডেটাসেটের বৈচিত্র্য জানা অত্যন্ত গুরুত্বপূর্ণ। এটি ডেটা কতটা ছড়ানো তা বোঝায়।
গড় বা মধ্যক প্রায়ই চরম মান দ্বারা প্রভাবিত হয়। বিস্তার পরিমাপ এটি সঠিকভাবে বুঝতে সাহায্য করে।
গবেষণায় ডেটাসেট কতটা সামঞ্জস্যপূর্ণ তা বিশ্লেষণের জন্য বিস্তার পরিমাপ প্রয়োজন।
উদাহরণ:
একটি ওষুধের কার্যকারিতা পরীক্ষা করতে বিস্তার পরিমাপ ব্যবহার করা হয়। কম বিস্তার মানে ওষুধটির কার্যকারিতা নির্ভরযোগ্য।
ডেটার বৈচিত্র্যের ভিত্তিতে ভবিষ্যৎ প্রবণতা অনুমান করা সহজ হয়।
বিস্তার পরিমাপ ঝুঁকি বিশ্লেষণে গুরুত্বপূর্ণ। এটি জানায় ডেটা কতটা পরিবর্তনশীল এবং সংশ্লিষ্ট ঝুঁকি কতটা বেশি।
বিস্তার পরিমাপ শুধু উপাত্তের বৈচিত্র্য নির্ণয় নয়, বরং বিভিন্ন সিদ্ধান্ত গ্রহণ, গবেষণার নির্ভুলতা নিশ্চিত করা, এবং ভবিষ্যৎ প্রবণতা নির্ধারণে গুরুত্বপূর্ণ ভূমিকা পালন করে। এটি উপাত্ত বিশ্লেষণের একটি অপরিহার্য অংশ।
একটি আদর্শ বিস্তার (Measure of Dispersion) ডেটাসেটের বৈচিত্র্য এবং পরিবর্তনশীলতা সঠিকভাবে বোঝাতে কিছু নির্দিষ্ট গুণাবলির অধিকারী হওয়া উচিত। সেগুলো নিম্নরূপ:
একটি আদর্শ বিস্তার সহজ, স্পষ্ট, সংবেদনশীল, এবং চরম মানের প্রভাব থেকে মুক্ত হওয়া উচিত। এটি পরিসংখ্যান বিশ্লেষণ এবং তুলনার জন্য কার্যকর হওয়া প্রয়োজন। ডেটার প্রকৃতি অনুযায়ী সঠিক বিস্তার পরিমাপ নির্বাচন গুরুত্বপূর্ণ।
ডেটাসেটের বৈচিত্র্য এবং ছড়িয়ে পড়া সম্পর্কে ধারণা পেতে বিস্তার পরিমাপ গুরুত্বপূর্ণ। প্রতিটি পরিমাপের নির্দিষ্ট বৈশিষ্ট্য এবং সুবিধা রয়েছে। নিচে বিস্তার পরিমাপের বিভিন্ন পদ্ধতির তুলনামূলক আলোচনা উপস্থাপন করা হলো:
বৈশিষ্ট্য:
সুবিধা:
অসুবিধা:
বৈশিষ্ট্য:
সুবিধা:
অসুবিধা:
বৈশিষ্ট্য:
সুবিধা:
অসুবিধা:
বৈশিষ্ট্য:
সুবিধা:
অসুবিধা:
বৈশিষ্ট্য:
সুবিধা:
অসুবিধা:
| বিস্তার পরিমাপ | সুবিধা | অসুবিধা | প্রভাবিত চরম মান দ্বারা? |
|---|---|---|---|
| বিস্তার (Range) | সহজ এবং দ্রুত গণনা | বহিরাগত মানের প্রভাব বেশি | হ্যাঁ |
| আন্তঃচতুর্থাংশ বিস্তার (IQR) | চরম মানের প্রভাব নেই | শুধুমাত্র মধ্যবর্তী ডেটা বিশ্লেষণ | না |
| গড় বিচ্যুতি (Mean Deviation) | সমস্ত মানের বৈচিত্র্য প্রকাশ | তুলনামূলক সময়সাপেক্ষ | কিছুটা |
| চতুর্ভাগীয় বিচ্যুতি | বহিরাগত মান দ্বারা প্রভাবিত নয় | সম্পূর্ণ ডেটা বিশ্লেষণ করে না | না |
| মান বিচ্যুতি (Standard Deviation) | ডেটাসেটের বৈচিত্র্যের সঠিক পরিমাপ | গণনা জটিল এবং বহিরাগত মানের প্রভাব | হ্যাঁ |
বিস্তার পরিমাপ নির্বাচন করার সময় ডেটাসেটের প্রকৃতি এবং প্রয়োজনীয় বিশ্লেষণের উপর নির্ভর করতে হয়।
বিভেদাঙ্ক (Measures of Dispersion) একটি ডেটাসেটের মানগুলোর বৈচিত্র্য বা ছড়িয়ে পড়া সম্পর্কে ধারণা দেয়। এটি ডেটার বিশ্লেষণে গুরুত্বপূর্ণ ভূমিকা পালন করে। বিভিন্ন পরিস্থিতিতে বিভেদাংকের প্রয়োজনীয়তা নিচে আলোচনা করা হলো:
বিভেদাঙ্ক ডেটাসেটের মানগুলোর মধ্যে কতটা ছড়িয়ে পড়া বা পরিবর্তনশীলতা আছে তা নির্ধারণ করে। এটি বোঝায় যে ডেটাগুলো গড়ের চারপাশে কতটা ঘনিষ্ঠভাবে বা দূরত্বে ছড়ানো।
উদাহরণ:
একটি কোম্পানির কর্মচারীদের বেতন বিশ্লেষণে বিভেদাঙ্ক ব্যবহার করলে বেতনের বৈচিত্র্য সম্পর্কে ধারণা পাওয়া যায়।
কোনো ডেটাসেট কতটা স্থিতিশীল তা বিভেদাঙ্কের মাধ্যমে নির্ধারণ করা যায়।
উদাহরণ:
বিনিয়োগের ঝুঁকি পর্যালোচনার ক্ষেত্রে বিভেদাঙ্ক ব্যবহৃত হয়।
দুটি বা ততোধিক ডেটাসেটের বৈচিত্র্যের তুলনা করতে বিভেদাঙ্ক অপরিহার্য।
উদাহরণ:
একটি স্কুলের দুটি ক্লাসের ছাত্রদের পরীক্ষার ফলাফলের বৈচিত্র্য তুলনা করার জন্য বিভেদাঙ্ক ব্যবহার করা হয়।
বিভিন্ন বৈজ্ঞানিক গবেষণায় বিভেদাঙ্ক ব্যবহার করে ডেটার বৈচিত্র্য বিশ্লেষণ করা হয়, যা সঠিক সিদ্ধান্ত গ্রহণে সহায়তা করে।
উদাহরণ:
স্বাস্থ্য গবেষণায় রোগীদের রক্তচাপের মানের বৈচিত্র্য নির্ধারণে বিভেদাঙ্ক ব্যবহৃত হয়।
বিভেদাঙ্ক ব্যবহার করে ডেটাসেটে বহিরাগত মান বা অস্বাভাবিক মান শনাক্ত করা যায়।
উদাহরণ:
একটি উৎপাদন প্রক্রিয়ায় যন্ত্রাংশের আকারের মধ্যে কোনো অস্বাভাবিক পরিবর্তন হলে বিভেদাঙ্কের সাহায্যে তা ধরা যায়।
পরিসংখ্যানিক মডেল তৈরিতে বিভেদাঙ্ক একটি গুরুত্বপূর্ণ উপাদান। এটি ডেটার বৈচিত্র্যের উপর ভিত্তি করে মডেলের নির্ভুলতা নিশ্চিত করতে সাহায্য করে।
বিনিয়োগ এবং ঝুঁকি ব্যবস্থাপনায় বিভেদাঙ্ক ব্যবহার করা হয়। ডেটার বৈচিত্র্য বিশ্লেষণ করে ঝুঁকি কমানোর কৌশল নির্ধারণ করা যায়।
উৎপাদন প্রক্রিয়ার গুণমান নিশ্চিত করতে বিভেদাঙ্ক ব্যবহৃত হয়।
উদাহরণ:
যদি উৎপাদিত পণ্যের বৈচিত্র্য কম থাকে, তবে পণ্যটি মানসম্পন্ন হিসেবে বিবেচিত হয়।
বিভেদাঙ্ক একটি গুরুত্বপূর্ণ পরিসংখ্যানিক মাপকাঠি যা ডেটাসেটের বৈচিত্র্য, স্থিতিশীলতা, এবং মানের প্রকৃতি বুঝতে সাহায্য করে। এটি সিদ্ধান্ত গ্রহণ, গবেষণা, এবং বিভিন্ন ক্ষেত্রের কার্যক্রম পরিচালনার জন্য অপরিহার্য। বিভেদাঙ্ক ছাড়া ডেটা বিশ্লেষণ অসম্পূর্ণ থেকে যায়।
পরিসংখ্যানের এই তিনটি গুরুত্বপূর্ণ মাপকাঠি ডেটাসেটের বৈচিত্র্য, স্থিতিশীলতা এবং তুলনামূলক বৈশিষ্ট্য নির্ধারণে ব্যবহৃত হয়। এগুলো সম্পর্কে বিস্তারিত আলোচনা নিচে উপস্থাপন করা হলো।
সংজ্ঞা:
ভেদাংক হলো একটি ডেটাসেটের মানগুলোর গড় থেকে কতটা বিচ্যুতি ঘটেছে তার গড় বর্গ। এটি ডেটাসেটের বৈচিত্র্য পরিমাপের জন্য একটি গুরুত্বপূর্ণ মাপকাঠি।
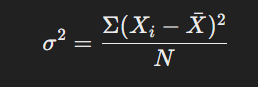
ভেদাংক নির্ণয়ের সূত্র:
যেখানে,

উদাহরণ:
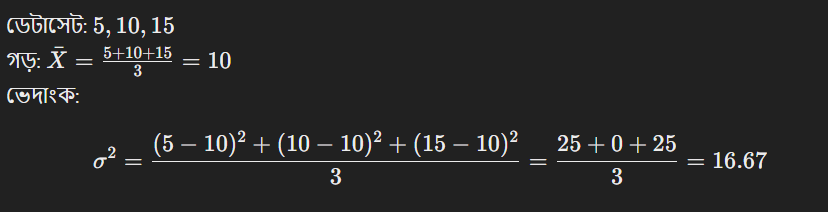
বৈশিষ্ট্য:
সংজ্ঞা:
বিভেদাংক হলো ডেটাসেটের মানগুলোর ছড়িয়ে পড়া বা বৈচিত্র্যের পরিমাপ। এটি ডেটার সর্বোচ্চ ও সর্বনিম্ন মানের মধ্যকার পার্থক্য, গড় থেকে বিচ্যুতি, বা অন্যান্য সূচকের মাধ্যমে নির্ধারণ করা হয়।
প্রকারভেদ:
১. বিস্তার (Range): সর্বোচ্চ এবং সর্বনিম্ন মানের পার্থক্য।
Range = Maximum Value - Minimum Value
২. আন্তঃচতুর্ভাগ বিস্তার (Interquartile Range - IQR):
IQR= Q3 - Q1
৩. গড় বিচ্যুতি (Mean Deviation):
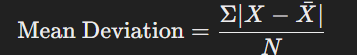
৪. মান বিচ্যুতি (Standard Deviation):
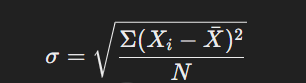
গুরুত্ব:
সংজ্ঞা:
সহভেদাংক হলো ডেটাসেটের মান বিচ্যুতি এবং গড়ের অনুপাত, যা শতাংশে প্রকাশ করা হয়। এটি বিভিন্ন ডেটাসেটের তুলনা করার জন্য ব্যবহৃত হয়।
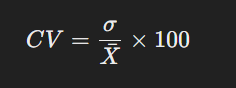
সহভেদাংক নির্ণয়ের সূত্র:
যেখানে,

উদাহরণ:

গুরুত্ব:
| বিষয় | ভেদাংক (Variance) | বিভেদাংক (Dispersion) | সহভেদাংক (CV) |
|---|---|---|---|
| সংজ্ঞা | ডেটার গড় থেকে বিচ্যুতির গড় বর্গ | ডেটার বৈচিত্র্য পরিমাপ | আপেক্ষিক বৈচিত্র্য শতাংশে প্রকাশ |
| পরিমাপের একক | ডেটার বর্গ এককে (Squared Units) | ডেটার মূল এককে (Original Units) | শতাংশে (Percentage) |
| ব্যবহার | বৈচিত্র্য এবং স্থিতিশীলতা নির্ধারণ | বৈচিত্র্যের প্রকৃতি বোঝার জন্য | তুলনামূলক বিশ্লেষণে |
| প্রভাবিত চরম মান দ্বারা | হ্যাঁ | নির্ভর করে | নির্ভর করে |
এই তিনটি মাপকাঠি ডেটা বিশ্লেষণে ভিন্ন ভিন্ন প্রয়োজনে ব্যবহৃত হয় এবং প্রতিটির নিজস্ব গুরুত্ব রয়েছে।
Read more

or




